|
|
1-5 Jul 2019 Paris (France)
|
|
|
|
|
Description
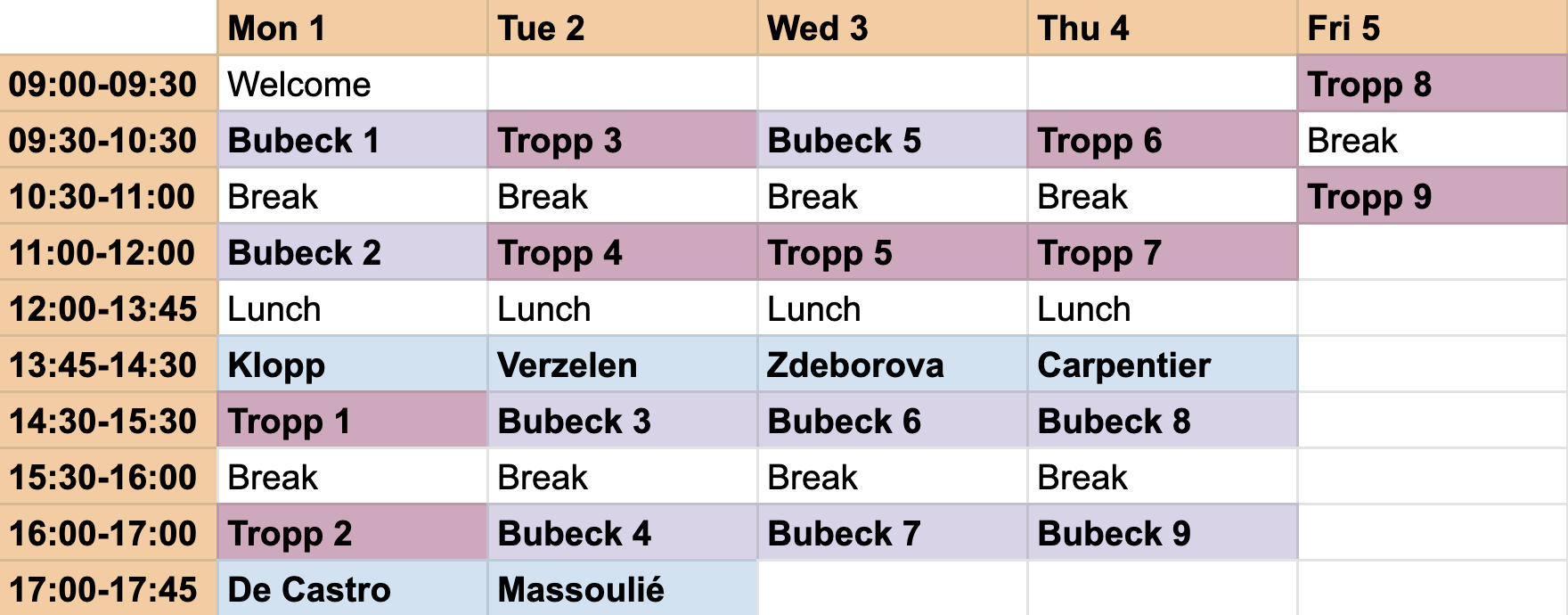
This one week summer school belongs to the PSL-maths program of the PSL university. It is devoted to High dimensional probability and algorithms. The targeted audience is young and less young mathematicians, starting from the PhD level. The school will take place in ÉNS Paris, from July 1 to 5, 2019.
|




| Online user: 2 |


|

{kind=link}
{kind=link}